Essentially, exceptions are a form of structured, non-local
goto with stack unwinding.
"Structured" here means "higher level than the
machine" (a matter of taste/opinion), and "non-local"
means "beyond a single function/method".
What this means is that you can replace code like (in "C"):
int bottom()
{
int things_go_wrong = -1; // For illustration
if (things_go_wrong) goto error;
return 0;
error:
return -1;
}
int
middle()
{
if (-1 == bottom()) goto error;
return 0;
error:
return -1;
}
void
top()
{
if (-1 == middle()) {
handle_failure();
}
}
With code like (in Java):
public class A {
void botton() {
boolean thingsGoWrong = true; // For illustration
if (thingsGoWrong) throw new ThingsWentWrong("So wrong!");
}
void middle() {
bottom();
}
void top() {
try {
middle();
} catch (ThingsWentWrong e) {
handleFailure();
}
}
}
"Unwinding" here means the compiler or runtime treats
intermediate calls (the stack) the same as if returning
normally (for example, the stack pointer is moved back;
and in a language like C++, destructors are executed), and
program execution resumes in the catch block.
It is "structured" in the sense that it is not the same as a
direct goto to the resume point. This is not
possible in standard "C" or C++ (or in Java), which only
suppport local labels within functions. The equivalent in "C"
and C++ is to use setjmp and
longjmp for a non-local goto, and forget
all about deallocating memory or calling destructors. (As odd as
this sounds, it is needed for call-with-continuation,
an important feature in
LISP-like languages).
Takeaway
All human endeavors build on the work of those who came
previous. Exceptions are no exception. They are the
result of 1960s and 1970s programmers
wanting an easier way to deal with
exceptional conditions. This is not completely identical
with "errors", which may sometimes be better represented with
a simple boolean true/false return.
Like any sharp instrument, do not abuse it.
You make it incredibly difficult to report issues about JIRA itself:
* I cannot use Markdown in the editor. You are the only tool I use which does
not support markdown. This is one of the top reasons I recommend against
using JIRA to clients Ex: quoting code with single backticks, or code blocks
with tripple backticks
* Finding the issue tracker for JIRA is a PITA. Even after finding it, when
creating a new issue, it offers a dialog/link that takes me back to the
beginning
* The web pages for a team project does not have any easy way to report JIRA
issues to Atlassian
* How do I find out the version of JIRA software in use when I report problems?
* Reporting to you, you _require__ a component, and severity. Which component
should I pick? I don't know how your product is architected, so I guessed
at one. And "affected version"? Heck if I know. Really, you can't
provide a link on a cloud JIRA board which fills this in automatically?
* In a dropdown for picking what Atlassian product to report against, the text
describing them is cut off. So when it says "XXX (includi)" I have no idea
what it is including
Only .. I didn't. Their publicly accessible issue tracker does not let me file issues.
We recently migrated a medium-sized Java project to Spring Boot 2
from version 1. One of the challenges was migrating to the JDK
date-time library from Joda. It turns out that Spring Boot 2 has
excellent native support for JDK date-times, as does Jackson (JSON)
and Hibernate (database), the default technologies offered by Spring
Boot 2 for these features.
The migration itself went smoothly, which is unsurprising given the
fantastic work of Stephen
Colebourne in designing JDK date-time support based on
his authorship of Joda.
So we looked at disabling Joda completely in our Gradle build.
The most concise approach we found was:
This removed Joda completely from configurations (classpaths) related
to Java. However, this had unintended side effects:
During tests, we needed Joda in the runtime classpath for a
3rd-party library, OpenSAML
During boot run (running the app), we needed Joda in the
classpath for another 3rd-party library, SpringFox
We easily found a workaround for SpringFox, but not for OpenSAML.
(If you're curious, yes, we do intent to migrate from OpenSAML 2
(desupported in 2016) to OpenSAML 3; however, we would like
spring-security-saml2-core support first.)
A solution in progress
The exclusion in the compile configuration does
exactly what we need: Joda disappears! But what to do
about SpringFox and OpenSAML?
For the Spring Boot runtime classpath, there is another concise
solution, though finding it was rather troublesome, and it is
not well-documented by Pivotal or in Stack Overflow.
First, we setup another classpath of our own making named
bootRuntime:
configurations {
// Other parts of "configurations", including the Joda exclusion from above
bootRuntime // Synthetic configuration for deps needed *only* to launch app
}
Then we added Joda to that synthetic classpath relying on Spring Boot
plugin's definition for the version of Joda to use:
dependencies {
// Other parts of "dependencies"
bootRuntime 'joda-time:joda-time'
}
Lastly, we taught Spring Boot to include this synthetic classpath
when launching our app (this was the trickiest part):
bootJar {
bootInf {
from configurations.bootRuntime
into 'lib'
}
}
bootRun {
classpath += configurations.bootRuntime
}
This adds Joda to the runtime classpath for both the single "fat
jar" built by Spring (bootJar), and when launching
the app on the command line with gradle (bootRun).
Unless you are a heavy Gradle user, from ... into ...
syntax may be unfamiliar: this copies the jars in the synthetic
configuration into the fat jar at the location Boot expects to find
them. The "'lib'" is literally a directory location within the
jar. Useful magic, but a bit obtuse. The outcome:
$ jar tf build/libs/the-project.jar | grep joda-time
BOOT-INF/lib/joda-time-2.9.9.jar
As a matter of fact, Joda is the very last file in the boot jar,
a suggestion that it was added by our bootInf section
after the Boot plugin built the jar.
(Our workaround is intentionally small. If we're unable to make
it work, we'll switch to brute-force library exclusions in our
dependencies lists. The goal is to prevent accidental import
from Joda, for example, of LocalDate.)
Remaining work
For running the boot app, this solution is great: it is small,
readable, easy to maintain, and it works. However, for
tests which exercise our user authentication with OpenSAML, it
fails. Joda is not in the test classpath, and we cannot use or
mock OpenSAML methods which use Joda types.
Barring another magical solution like bootRuntime,
we'll fall back on manually excluding Joda from each dependency,
and adding it back in to the test classpath. A pity given how
pithy the solution is with exclusion from the
compile configuration.
Kotlin does many wonderful things for you. For example, the data classes
create helpful constructors, and automatically implement
equals and hashCode in a reasonable
way.
So how do I test that my Kotlin entity is correctly annotated
for JPA? The simplest thing would be a "round trip" test:
create an entity, save it to a database, read it back, and
confirm the object has the same values. Let's start with a
simple entity, and the simplest possible test:
@Entity
data class Greeting(
val content: String,
@Id @GeneratedValue
val: Int id = 0)
@DataJpaTest
@ExtendWith(SpringExtension::class)
internal class GreetingRepositoryIT(
@Autowired val repository: GreetingRepository,
@Autowired val entityManager: EntityManager) {
@DisplayName("WHEN saving a greeting properly annotated")
@Nested
inner class Roundtrip {
@Test
fun `THEN is can be read back`() {
val greeting = Greeting("Hello, world!")
repository.saveAndFlush(greeting.copy())
entityManager.clear()
assertThat(repository.findOne(Example.of(greeting)).get())
.isEqualTo(greeting)
}
}
}
Some things to note:
To ensure we truly read from the database, and not the
entity manager's in-memory cache, flush the object and
clear the cache.
As saving also updates the entity's id field,
save a copy, so our original is untouched.
Be careful to use saveAndFlush on the Spring
repository, rather than entityManager.flush(),
which requires a transaction, and would add unneeded
complexity to the test.
But this test fails! Why?
The unsaved entity (remember, we made a copy to keep the
original pristine) does not have a value for id,
and the entity read back does. Hence, the automatically
generated equals method says the two objects
differ because of id (null in the
original vs some value from the database).
Further, the Spring Data QBE (QBE) search
for our entity includes id in the search criteria. Even
changing equals would not address this.
What to do?
The solution
It turns out we need to address two issues:
The generated equals takes id into
account, but we are only interested in the data values, not
the database administrivia.
The test look up in the database includes the SQL
id column. Although we could try
repository.getOne(saved.id), I'd prefer to
keep using QBE, if the code is reasonable.
To address equals, we can rely on
an interesting fact about Kotlin data classes: only
default constructor parameters are used, not properties in the
class body, when generating equals and
hashCode. Hence, I write the entity like this,
and equals does not include id, while
JPA is stil happy as it relies on getter reflection:
@Entity
data class Greeting(
val content: String) {
@Id
@GeneratedValue
val id = 0
}
To address the test, we can ask QBE to ignore id when
fetching our saved entity back from the database:
@DataJpaTest
@ExtendWith(SpringExtension::class)
internal class GreetingRepositoryIT(
@Autowired val repository: GreetingRepository,
@Autowired val entityManager: EntityManager) {
@DisplayName("WHEN saving a greeting properly annotated")
@Nested
inner class Roundtrip {
@Test
fun `THEN is can be read back`() {
val greeting = Greeting("Hello, world!")
repository.saveAndFlush(greeting.copy())
entityManager.clear()
val matcher = ExampleMatcher.matching()
.withIgnoreNullValues()
.withIgnorePaths("id")
val example = Example.of(greeting, matcher);
assertThat(repository.findOne(example).get()).isEqualTo(greeting)
}
}
}
In a larger database, I'd look into providing an
entity.asExample() to avoid duplicating
ExampleMatcher in each test.
Java approach
The closest to Kotlin's data classes for JPA entities is Lombok's
@Data annotation, together with
@EqualsAndHashCode(exclude = "id") and
@Builder(toBuilder = true), however the
expressiveness is lower, and clutter higher.
The test would
be largely the same modulo language, replacing
greeting.copy() with
greeting.toBuilder().build(). Alternatively,
rather than a QBE matcher, one could write
greeting.toBuilder().id(null).build().
This last fact leads to an alternative with Kotlin: include
id in the data class' default constructor, and in
the test compare the QBE result as
findOne(example).get().copy(id = null) without
a matcher.
My team is working on a Java server, as part of a larger project
project, using Gradle to build and JaCoCo
to measure testing code coverage. The build fails if coverage
drops below fixed limits (branch, instruction, and
line)—"verification" in JaCoCo-speak.
We follow the strategy of The
Ratchet: as dev pairs push commits into the project, code
coverage may not drop without group agreement, and if coverage
rises, the verification limits rise to match. This ensures we
have ever-rising coverage, and avoid new code which lacks
adequate testing.
The problem
At a work project, we're struggling to get JaCoCo to ignore some
new, configuration-only Java classes. These classes have no
"real" implementation code to test, are used to setup
communication with an external resource, yet are high
line-count (static configuration via code). So they drag down
our code coverage limits, and there is no effective way to
unit test them sensibly. (They are best tested as system
tests within our CI pipeline using live programs and remote
resources.)
JaCoCo has what seems at first blush a sensible way to exclude
these configuration classes from testing:
Something to consider: using wildcards
(hm.binkley.labs.saml.*) may take additional work.
Why?
Why does this work, and the "obvious" way does not?
JaCoCo has more than one notion of scoping. The clearest one is the
counters: branches, classes, instructions, lines,
and methods.
Not as well documented is the
scope of checks: bundles, classes, methods, packages, and
source files. These are not mix-and-match. For
example, exclusions apply to classes. Lyudmil Latinov has the
best hints I've found on how this works.
I'd like to use jenv on my Cygwin setup at home. Oracle has
moved to a 6-month release pace, and so I find myself dealing with
multiple Java major verions. However, my tool of choice, jenv,
does not play well with Cygwin.
(Note: There are twojenvs out there. I am talking
about jenv.be, not jenv.io. Apologies that neither does
HTTPS well.)
As a workaround, I wrote a straight-forward shell function to provide the
minimum I need: switch between versions in the current shell:
# Until jenv.be supports Cygwin
function set-java {
local -a java_v
local jdk v OPTIND
for jdk in /cygdrive/c/Program\ Files/Java/jdk*
do
jdk="${jdk/\/cygdrive\/c\/Program\ Files\/Java\/jdk/}"
v=${jdk#-}
v=${v#1.}
v=${v%%.*}
java_v[$v]=$jdk
done
local verbose=false
while getopts :hv opt
do
case $opt in
h ) cat <<EOH
Usage: $FUNCNAME [-hv] VERSION
Options:
-h Print help and exit
-v Verbose output
Arguments:
VERSION One of ${!java_v[@]}
EOH
return 0 ;;
v ) verbose=true ;;
* ) echo "Usage: $FUNCNAME [-hv] VERSION" >&2 ; return 2 ;;
esac
done
shift $((OPTIND - 1))
case $# in
1 ) ;;
* ) echo "Usage: $FUNCNAME [-hv] VERSION" >&2 ; return 2 ;;
esac
if ! [[ ${java_v[$1]+foo} ]]
then
echo "$FUNCNAME: No such Java version: $1. Try $FUNCNAME -h" >&2
return 2
fi
export JAVA_HOME='C:\Program Files\Java\jdk'${java_v[$1]}
for v in ${!java_v[@]}
do
case $v in
$1 ) ;;
* ) export PATH="${PATH//${java_v[$v]}/${java_v[$1]}}" ;;
esac
done
if $verbose
then
echo "$FUNCNAME: Updated JAVA_HOME and PATH for JDK to $v at $JAVA_HOME"
fi
}
What is my dream story card? I don't mean: What's the story
I'd most like to work on! I mean: What should a
virtual story card look like (as opposed to card stock on
a wall)? This may be a trivial question. But for me the
user experience working with stories is very
important: I work with them daily, write them, discuss them,
work on them, accept them, etc. I want the feel of the card to be
thoughtful, like that fellow to the right.
And more than that. I am lazy, impatient, hubristic. The
acceptance criteria, I want them testable,
literally testable in that each has a matching test I can
execute. Given my laziness, I don't want to switch systems
and run tests; I'd like to execute acceptance criteria directly
from the story card.
So is there a system like that today? No. There are bits and
pieces though.
Not all story card systems are equal
Some story card systems are particularly awkward to read,
understand or use. Special demerits for:
A hard-coded workflow that the team cannot be change to fit
how they work: the team is expected to fit the tool
Workflow state transition buttons are nice, but not so
nice is unconfigurable labels, especially when the button
labels are misleading
A hard-coded or limited hierarchy of stories, so if a
team uses epics or features or
themes or whatever to organize stories, and there
are more than one level to this, the team is out of luck
Lack of quality RESTful support, in particular, no simple
identifier for story cards, so linking directly to cards is
opaque, useless or completely absent
A scenario
Post-development testing on this team is a fairly ordinary role.
The developers say: a new web page is ready. Testers then
validate the same page features each time for each new page,
simple things:
Can an account with security role X log in?
Can X submit the form? (Or not submit if
forbidden?)
What form defaults appear for role X? Do they
reflect role X?
(Yes, I know — what about developer testing? Bear with
me.)
On it goes, the same work each time. Redundant, repetitive,
error-prone, fiddly. And worst of all—boring,
BORING! This is traditional, manual "user
testing" at its worst.
What's to be done?Can we fix this?
After all, the testing is valuable: nobody wants broken web pages;
everybody wants to log in. But the tester is valuable, too,
more valuable even: is this the most valuable testing
a human could do? Surely people are more clever, more
insightful than this. And what about all the other page
features not tested because of time spent on the basics?
Well, people are more clever than this.
Clearing the path
What guides testing? If you're using nearly any form of modern user
story writing, this includes something like "Acceptance Criteria".
These are the gates that permit story development to be called
successful: the testers are gatekeepers in
the manual testing world. In the manual world these
criteria might be congregated into a single "Requirements
Document" or similar (think: big,
upfront design).
We can do better! Gatekeeper-style testing assumes a linear path
from requirements to implementation to testing, just as waterfall
considers these activities as distinct phases. But we know
agile approaches do better than waterfall in most cases. Why
should we build our teams to mirror waterfall? Of course the
answer is to structure teams to look agile, just as the team
itself practices agile values.
So how do we make Acceptance Criteria more agile?
Enter the Three Amigos
In current agile practice, a story card is not a ready to play
until approved by the The Three Amigos: BA, Dev,
QA. Each plays their part, brings their
perspective, contributes to meeting team-agreed "Definition of
Ready".
A key component of playable cards are the
Acceptance Criteria — answering the question,
"What does success look like?" when a story is finished.
The perspectives include:
BA: Is the story told right? — What
is the way to describe the work?
Dev: Is the story the right size? —
What is the complexity of the work?
QA: Is it the right story to tell? —
What is the value of the work?
What are Acceptance Criteria?
But where does this simple testing come from? Any software delivery
process beyond "winging it" has some requirements
Well-written agile stories have Acceptance Criteria. What are
these? An Acceptance Criteria (AC) is a statement in a story that
a tester (QA) can use to validate that all or a portion of the
story is complete. The formulaic phrasing for ACs I like best
is:
GIVENsome state of the
world WHENsome change
happens THENsome observable
outcome results
Generally for web applications this means when I do something with
a web page in the application, then the page changes in some
particular way or submits a request and the response page has
some particular quality or property (or the negative case that
is does not have that quality or property).
In some cases it is even simpler: just check that a particular web
address fully loads, for example, when testing login access to
pages.
So what's the question?
Wherever possible we want to automate. If something can be done for
us by a computing machine, we don't want to spend human time on
it. Humans can move on to more interesting, valuable work when
existing tasks can be automated.
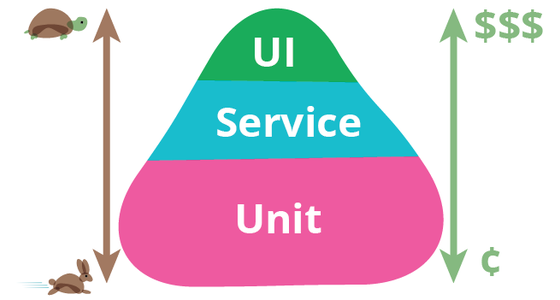
Consider the Test Pyramid (image right): automating
lower-value tests focuses people on higher-value ones. You get
more human attention and insight on the kinds of tests which best
improve the value of software. You win more.
The Story
This is a sample story card with a simplistic implementation of
AACs. Live buttons call back into the story system, to be
mapped to calls in the testing system. (Another
implementation might have the buttons directly call to the
testing system, avoiding an extra call into the story system
but showing details in the page source about the testing
system.)
Title
Narrative
AS A AAC author I WANT a mock executable
story SO THAT others can see
the value
Details
No actual criteria were validated in the execution of
these tests. This is only a mock.
GIVEN magical thinking WHEN in Missingland THEN there's no test
No test (yet) - create
one!
GIVEN magical thinking WHEN in Newland THEN nothing has happened yet
Test never run - be the
first!
GIVEN magical thinking WHEN in Fastland THEN tests run quickly
15% done (3s)
GIVEN magical thinking WHEN in Happyland THEN Unicorns
GIVEN magical thinking WHEN in Sadland THEN there be Dragons
Expected:
Dragons, got: Puppies
GIVEN magical thinking WHEN in Crazyland THEN nothing works right
Test timed out
after 90 seconds
GIVEN magical thinking WHEN in Slowland THEN tests are disabled
@dev1 @qa2: BLOCKED on
widget spanner
Acceptance Criteria states
Every AC potentially has a message from the testing system
giving more detail on state. These are noted below.
Missing
This AC has no matching test in the testing system. Use
the Create button to create a new test. This does
not run the test.
The message is boilerplate to remind users to
create tests.
Untested
The AC has a matching test in the testing system, but the
test has never been run. Use the Test button to
run the test.
Typically there is no message for this state.
Running
The matching test for the AC is running in the testing
system. Use the Cancel button to stop the test,
or wait for it to complete.
The message, is supported by the testing
system, should give a notion of progress. See REST
and long-running jobs for how to do this.
Passed
The matching test for the AC passed last time it ran.
Use the Test button to run the test again.
Typically there is no message for this state.
Failed
The matching test for the AC failed last time it ran.
Use the Test button to run the test again.
The message must give a notion of why the test
failed.
Errored
The matching test for the AC errored last time it ran.
Use the Test button to run the test again.
The message must give a notion of why the test
errored.
Disabled
The matching test for the AC is disabled in the testing
system. Update the testing system to reenable.
The message, if supported, should give a
reason the test is disabled when available.
Potential problems
Nothing is free. Potential problems with AACs include:
Integrations
There are no existing
integrations along these lines. You need to build your
own against JIRA, Mingle, FitNesse, Cucumber, etc. Whether
the story system drives the interaction, or the test
system does, may depend on the exact combination. Best
would be if both systems can call the other.
Scaling
As more AACs run, the complete suite takes longer. For
example, adding 1 minute of AAC/story, and 5
stories/iteration, in a 12 iteration project takes 60
minutes to run. This is not specific to AACs but a
general problem with acceptance tests. It's still much
cheaper than the manual steps for each test, but
prohibitive for a developer to run the whole suite
locally.
Best practice is for the 3 amigos to run only
the tests specific to a story before calling that story
Ready to Accept.
Update
Until I published this post on Blogger, I really wasn't certain how
it would look on that platform. I manually tested the visuals from
Chrome with the
local post, and it looked good. After seeing it in
Blogger, however, the "aside" sections are laid out poorly,
overlapping the text. I won't relay the page: mistakes are the
best way to improve, and a subtext of this post is Experiment
& Learn Rapidly. Public experiements are the most
faithful kind: no opportunity to fudge and pretend all was well on
the first try.
(I talk about myself in the post more than usual. I'm expressing
opinions more than usual, rather than observations and advice.
Caveat lector. Also, this post is link-rich.)
The stack
After reading Eric S. Raymond (ESR)'s posts on the
post-"C" world, I realized that I, too, live in that world. What
would my ideal language stack look like for 2018?
Each of these languages hits a sweet spot, and displaces an earlier
language which was itself a sweet spot of its time:
Bash and Perl →
Python
Java → Python and Kotlin
"C" and C++ → Kotlin and Go
An interesting general trend here: Not just replace a language with
a more modern equivalent, but also move programming further away
from the hardware. As ESR points out, Moore's law and
improving language engineering have raised the bar.
(ESR's thinking has evolved
over time, a sign of someone who has given deep and sustained
thought to the subject.)
About my experience with these languages
Python
I have moderate experience in Python spread out since the
mid-90s. At that time, I was undecided between Python, Ruby
and Perl. Over my career I worked heavily in Perl (it paid
well, then), some in Ruby (mostly at ThoughtWorks), and
gravitated strongly to Python, especially after using it
at Macquarie commodities trading where it was central to their
business.
Kotlin
I've been a Kotlin fan since it was announced. It scratches itches
that Java persistently gives, and JetBrains is far more
pleasant a "benevolent
dictator" than Oracle: JetBrains continually sought input
and feedback from the community in designing the language, for
example. Java has been my primary language since the late 90s,
bread and butter in most projects. If JetBrains keeps Kotlin in
its current directions, I expect it to displace Java, and
deservedly so.
Go
This is where I am relying on the advice of others more than
personal experience. I started programming with "C" and LISP
(Emacs), and quickly became an expert (things being relative) in
C++. Among other C++ projects, I implemented for INSO (Microsoft
Word multilingual spell checker) a then new specification for
UNICODE/CJKV support in C++ (wstring
and friends). I still love "C" but could do without C++. Go seems
to be the right way to head, especially with garbage collection.
With Ken Thompson and Rob Pike behind
it, intelligent luminaries like ESR pitching for it, and
colleagues at ThoughtWorks excited to start new Go projects, it's
high time I make up this gap.
What makes a "modern" language?
I'm looking for specific things in a "modern" language,
chiefly:
Kotlin is the interesting case. Though low in the rankings,
because of 100% interoperability running on the JVM, it's easy
to call Java from
Kotlin and call Kotlin from
Java, so the whole Java ecosystem is available to
Kotlin natively.
Further, Google fully supports Kotlin on
Android as a first-class language, so there is a wealth of
interoperability there. (The story for iOS is more nuanced,
with Kotlin/Native including that platform as a target but in
progress.)
Among Go's advantages over "C" and C++ is solid
garbage collection out of the box,
though Boehm a
valiant effort. It's only been since 1959.
No modern programmer—short of special cases—should
manually manage memory.
Kotlin gets a head start here. It's built
on the JVM (when targeting that environment), which has
arguably the world's greatest GC (or at least most tested).
It definitely gives you a
choice of garbage collectors. There's too much to
say about GC on the JVM for this post except that it is
first-rate.
Python has garbage collection. Though not
as strong as the JVM, it continues
to improve. It is unusual for GC to become a limiting
factor in a Python program; you
will know if it does.
(If you are in "C" or C++, and want some of the benefits of
GC, do consider
the Boehm-Demers
-Weiser garbage collector. No, you won't get the
fullest benefits of a language built for GC, but you'll get
enough to help a lot, even if just for leak detection.)
Static type inference
Kotlin really demonstrates where Java could
improve by leaps rather than baby
steps: automatic type inference. At least Java is
heading in the right direction. Don't tell the computer how
to run your program when it can figure this our for itself!
Keep your focus on what the program is for.
Interestingly, Kotlin and Go have strong
typing out of the box, but not Python. Python
has built-in support for typing, and an
excellent optional implementation, mypy,
however this is type declaration not type
inference, so it loses a bit there. And none of the
common alternatives (Ruby, Perl, PHP, etc.) have type
inference either. I'll need to check again in a few years, and
possibly update this choice.
(Paul Chiusana writes on
the value of static type checking.)
Rich ecosystem
Of the languages, Kotlin is a standout here.
Because it is a JVM language, it is 100% compatible with
Java, and can fully use the rich world of Java libraries
and frameworks. The main weakness for Kotlin is lack of
tooling: because more advanced tools may make assumptions
about bytecode, Kotlin's particular choices of emitted
bytecode sometimes confuse them.
Close behind is Python, "batteries
included" and all, and it has a better organized and
documented standard library than Java. For some problem
domains, Python has a richer ecosystem, for example, SciPy and NumPy is the best
math environment available in any language. (Some
specialty languages like MATLAB
deserve mention—an early employer of mine.) I may need
to reconsider my ranking Kotlin over Python here.
Go is, frankly, too new to have developed an
equivalent ecosystem, and full-blown package management is
still a
work in progress.
Concision and convenience
A common thread in recent language development is lower
ceremony: fewer punctuation marks and boilerplate; make
the machine do more work, you do less. Kotlin provides the
most obvious example compared to Java. Go is know for
cleanness and brevity. And Python ranks high here as well.
(Donnie Berkholz writes an
interesting post on ranking language
expressiveness.)
Code samples
The classic "Hello, World!" showing three things:
Writing a "main" callable from the command line
Using standard output to print to console
String formatting to build the output message
This doesn't, of course, give a sense of how these languages in
their full spectrum, but does give a first taste.
Java
Java in a file named MyStuff.java:
package my.stuff;
public final class MyStuff {
public static final String LANGUAGE = "Java";
public static void main(final String... args) {
System.out.println(String.format("Hello, World, from %s", language));
}
}
Kotlin
Kotlin in a file named my-program.kt:
package my.stuff
const val LANGUAGE = "Kotlin"
fun main(args: Array<String>) = println("Hello, World, from $LANGUAGE")
Go
But also compare Go to C++:
package main
import "fmt"
const Language = "Go"
func main() {
fmt.Println("Hello, World, from", Language)
}
As usual, I never catch as many problems in my writing as I do
after reading it posted publically. Many small edits, and an
added, explicit mention of wstring.