Good mocking advice from Naresh Jain, Mocking only Abstract Methods using Mockito (Partial Mocking). Note the trickiness of partial mocking in Mockito.
Saturday, December 07, 2013
Wednesday, December 04, 2013
10 Java dos and dont's
Nice list of 10 Java coding pratices from Data Geekery GmbH in Switzerland. These 10 are close to my programmer heart:
- Remember C++ destructors
- Don’t trust your early SPI evolution judgement
- Avoid returning anonymous, local, or inner classes
- Start writing [functional interface]s now!
- Avoid returning null from API methods
- Never return null arrays or lists from API methods
- Avoid state, be functional
- Short-circuit equals()
- Try to make methods final by default
- Avoid the method(T…) signature
Thursday, November 28, 2013
Great sources of information on Java 8 lambdas
I read a great post on Java 8 lambdas today by Javin Paul, full of references.
Saturday, November 23, 2013
Generic logback.xml
I've started using a generic logback.xml file for my projects which use logging:
<?xml version="1.0"?>
<configuration debug="${log.debug:=false}">
<property resource="logback-style.properties"/>
<appender name="console"
class="ch.qos.logback.core.ConsoleAppender">
<encoder
class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>${${log.style:-standard}}</pattern>
</encoder>
</appender>
<root level="${log.level:-warn}">
<appender-ref ref="console"/>
</root>
<include resource="logback-included.xml" optional="true"/>
<contextListener
class="ch.qos.logback.classic.jul.LevelChangePropagator"/>
<jmxConfigurator/>
</configuration>
Some explanation:
- I make use of the substitution
with default
feature to make use of system properties:
log.debug- Setting this to "true" gets logback to log during configuration, default is "false"
log.style- See below
log.level- This adjusts the global log level, default is "warn" so only errors and warnings log
- Reading variables from a property file as a resource lets me externalize them to the classpath, in particular, the log style (see the next item).
- The name
nesting for substitution feature is neat: it lets you use the value of a variable
as the name of another variable. For
log.styleI read a log format string from a properties file, using another property for the key name. - File inclusion let me keep the boilerplate in this example, and the application-specific bits in a separate logback XML file.
- Lastly I add a context listener to hook
java.util.logginginto logback and turn on JMX support. I do these last for some small performance gain.
Here is one example log-style.properties:
standard=%date{yyyy-MM-dd'T'HH:mm:ss.SSS'Z',UTC} %level [%thread] %logger - %message%n
Update:
A handy trick to automatically lower logging to "debug" when "logback.debug" is true, best placed near the top:
<if condition='property("logback.debug").equals("true")'>
<then>
<variable name="log.level" value="debug"/>
</then>
</if>
Wednesday, October 30, 2013
Cautionary tale
Toyota is a cautionary tale for following good practice at software.
Friends don't let friends smash their own stack.
Tuesday, October 29, 2013
Explaining LISP right
Are you a C++ programmer? Sergey Mozgovoy explains LISP to you. Are you not a C++ programmer? This is still a good post. He discusses LISP well and concisely.
Saturday, October 19, 2013
Doing Java file I/O right
Rick Hightower writes I wrote up a small example that shows how to use the FileSystem, URL, Reader, Pattern, Objects, InputStream, URL, URI, etc., really chock full of good practice tidbits. His post is focused on file I/O but the recommendations are good anywhere.
Friday, October 18, 2013
Signing maven releases with gpg while keeping your passphrase secure
On the road towards putting sample code into Maven Central I stumbled at GPG signatures of my artifacts. The problem was how to handle my passphrase.
The recommended solutions (one source of many) all had shortcomings:
- Prompting for your passphrase is often unuseful and is broken when running maven in Cygwin.
- Putting your passphrase on the command-line is visible to ps and is saved in history.
- Putting your passphrase into {{settings.xml}} leaves it on disk.
- Putting your passphrase on removable media and linking to it in {{settings.xml}} is awkward.
- Using a gpg agent would be best, but I did get everything hooked up right; I should investigate further.
- I will not even entertain removing the passphrase from my secrets just to satisfy maven.
A little think and some trial and error led me to:
- In
pom.xmlenable maven-pgp-plugin and configure maven-release-plugin:<plugin> <artifactId>maven-release-plugin</artifactId> <configuration> <arguments>-Dgpg.passphrase=${gpg.passphrase}</arguments> </configuration> </plugin> - In
settings.xmladd a profile:<profile> <id>gpg-sign</id> <activation> <activeByDefault>true</activeByDefault> </activation> <properties> <gpg.passphrase>${env.GPG_PASSPHRASE}</gpg.passphrase> </properties> </profile> - Write a small helper shell script:
#!/usr/bin/bash read -er -p 'Passphrase: ' gpg_passphrase echo # Get back newline GPG_PASSPHRASE="$gpg_passphrase" exec "$@"
The key observation is that environment variables are private to the process, in memory and transient. I invoke thus:
$ ./rls mvn clean verify Passphrase: [INFO] Scanning for projects...
Thursday, October 17, 2013
Chaining exceptions in Java 7
I used to write code like this when transmogrifying an exception:
try {
// Something broken
} catch (final RandomUninformativeException e) {
final Bug x = new Bug(format("Sprocket sprung a leak: %s", e));
x.setStackTrace(e.getStackTrace());
throw x;
} The intent was to turn a less meaningful exception into a more meaningful one. This was especially useful for log grepping. Most times I could chain the caught exception in the constructor of the thrown one (new BlahException(message, e)) but some exceptions do not have this constructor (e.g., NullPointerException).
With Java 7 I have a more expressive way:
final Bug x = new Bug(format("Sprocket sprung a leak: %s", e));
x.addSuppressed(e);
throw x You may add as many suppressed exceptions as you like, they all show up nicely (output from some test code):
java.lang.NullPointerException: Outer! at scratch.ExceptionMain.main(ExceptionMain.java:11) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:120) Suppressed: java.lang.NullPointerException: Inner! at scratch.ExceptionMain.main(ExceptionMain.java:12) ... 5 more Suppressed: java.lang.NullPointerException: Second! at scratch.ExceptionMain.main(ExceptionMain.java:13) ... 5 more
Monday, October 14, 2013
State of the art Java lock-free queues
Nitsan Wakart writes on optimizing SPSC lock-free queues (single producer, single consumer) with lots of code samples, performance data and refernces. Even the comments are interesting. An excellent read to understand state of the art in Java.
A random blub:
There are a few subtleties explored here:
- I'm using Unsafe for array access, this is nothing new and is a cut and paste job from the AtomicReferenceArray JDK class. This means I've opted out of the array bound checks we get when we use arrays in Java, but in this case it's fine since the ring buffer wrapping logic already assures correctness there. This is necessary in order to gain access to getVolatile/putOrdered.
- I switched Pressanas original field padding method with mine, mostly for consistency but also it's a more stable method of padding fields (read more on memory layout here).
- I doubled the padding to protect against pre-fetch caused false sharing (padding is omitted above, but have a look at the code).
- I replaced the POW final field with a constant (ELEMENT_SHIFT). This proved surprisingly significant in this case. Final fields are not optimized as aggressively as constants, partly due to the exploited backdoor in Java allowing the modification of final fields (here's Cliff Click's rant on the topic). ELEMENT_SHIFT is the shift for the sparse data and the shift for elements in the array (inferred from Unsafe.arrayIndexScale(Object[].class)) combined.
Thursday, October 10, 2013
Better Java properties handling
Luigi R. Viggiano provides OWNER API, a clever, better way to handle Java properties.
Essentially he maps properties in a general sense onto Java interfaces, using annotations to guide sourcing and processing. This is going directly into my projects.
I wrote a similar library based on interfaces to access properties, but using inheritance, implementation and generics with a set of helper base classes. His approach is superior.
@Sources({ "file:~/.myapp.config",
"file:/etc/myapp.config",
"classpath:foo/bar/baz.properties" })
public interface ServerConfig extends Config {
@Key("server.http.port")
int port();
@Key("server.host.name")
String hostname();
@Key("server.max.threads");
@DefaultValue("42")
int maxThreads();
} Interfaces to access properties is right. Among benefits you get strong typing of configuration and your IDE provides code completion.
Saturday, October 05, 2013
HTML5 quoting
Great explanation in Quoting and citing with <blockquote>, <q>, <cite>, and the cite attribute.
PIP 446
From the difficulties of advancing a well-established code base:
We are aware of the code breakage this is likely to cause, and doing it anyway for the good of mankind. (Details in the section "Backward Compatibility" below.)
Thursday, September 12, 2013
Quality
Nikita Salnikov-Tarnovski explains why his company moved to IntelliJ from Eclipse. Amen, brother.
Tuesday, September 10, 2013
Friday, August 30, 2013
Overwhelmed: git flow, github, maven and central
I decided to publish code to Maven central providing extended version of this blog's sample code. And I have become fascinated with gitflow. So I am stirring the pot, mixing git, github, maven and the central repo. Wish me luck. I'll post a "howto" when it works well enough.
Quick tour of Java 8
Bienvenido David III provides a quick tour of Java 8 in Everything About Java 8.
Rebooting Jigsaw redux
Alex Blewitt has interesting observations on the next reboot of Jigsaw, the project to modularize the JDK, in Jigsaw, Second Cut. Amusing bit:
There has been a module system available for Java from the early days, known as JSR 8 and more recently as OSGi and JSR 291, that is used by all major Java EE application servers, and many other systems and applications in wide use today (JIRA, Eclipse) as well as specific vertical markets (embedded systems, home automation). Jigsaw follows in the footsteps of design successes such as
java.util.Date, JavaIONIONIO2NIO2.2 and thejava.loggingpackage, and aims to ignore best practices to developer an inferior system for use by the JDK itself.
Ultimately he hopes for OSGi-lite.
Thursday, August 29, 2013
Netflix contributes RxJava
Somehow I missed this earlier: Functional Reactive in the Netflix API with RxJava by Ben Christensen. It begins:
Our recent post on optimizing the Netflix API introduced how our web service endpoints are implemented using a "functional reactive programming" (FRP) model for composition of asynchronous callbacks from our service layer.
This post takes a closer look at how and why we use the FRP model and introduces our open source project RxJava – a Java implementation of Rx (Reactive Extensions).
Sunday, August 25, 2013
Providing failure policy with generics and annotations
Java generics with annotations provides a simple technique for specifying failure policies in an API. The exception in a throws clause may be a generic parameter. The @Nullable and @Nonnull annotations express intent.
In the example, Base takes an Exception as a generic parameter. Three implementations demonstrate the choices:
ReturnsNullis for "finder" type APIs, where anullreturn is in good taste.ThrowsUncheckedis when failure is fatal, and should be handled higher in the stack.ThrowsCheckedis when failure is transient, and can be handled by the caller (e.g., network failures).
Because the exception is defined at a class level, this technique is best for SAM-style APIs or when a common exception is shared by a few calls.
static void main(final String... args) {
new ReturnsNull().returnSomething();
System.out.println("Returned null");
try {
new ThrowsUnchecked().returnSomething();
} catch (final RuntimeException ignored) {
System.out.println("Threw unchecked");
}
try {
new ThrowsChecked().returnSomething();
} catch (final Exception ignored) {
System.out.println("Threw checked");
}
}
interface Base<E extends Exception> {
Object returnSomething() throws E;
}
final class ReturnsNull implements Base<RuntimeException> {
@Nullable @Override
public String returnSomething() {
return null;
}
}
final class ThrowsUnchecked implements Base<RuntimeException> {
@Nonnull @Override
public String returnSomething() {
throw new RuntimeException();
}
}
final class ThrowsChecked implements Base<Exception> {
@Nonnull @Override
public String returnSomething() throws Exception {
throw new Exception();
}
}
Tuesday, July 30, 2013
Extending String in Java with enums
Without extension methods in Java 8 (or without changing JVM language) one cannot extend String. Or can one?
public final class ExtendStringWithEnum {
public static void main(final String... args) {
out.println(format("%s: %s", APPLE, toCrAzYcAsE(APPLE)));
out.println(format("%s: %s", BANANA, BANANA.toCrAzYcAsE()));
}
public enum EnumConstants {
APPLE("apple"), BANANA("banana");
private final String value;
EnumConstants(final String value) {
this.value = value;
}
public String toCrAzYcAsE() {
return ExtendStringWithEnum.toCrAzYcAsE(value);
}
@Override
public String toString() {
return value;
}
}
public static final class StringConstants {
public static final String APPLE = "apple";
public static final String BANANA = "banana";
}
public static String toCrAzYcAsE(final String value) {
final StringBuilder builder = new StringBuilder(value.length());
for (int i = 0, x = value.length(); i != x; ++i)
builder.append(
0 == i % 2 ? toUpperCase(value.charAt(i))
: toLowerCase(value.charAt(i)));
return builder.toString();
}
} Given suitable static imports, the code in "main" for APPLE is how I write it using string constants; the code for BANANA is how I write it for enum constants wrapping strings, and how I would like to write it for strings as well using the static "toCrAzYcAsE" methods. Maybe Java 9.
Thursday, July 25, 2013
OOPs
John D. Cook notes in Too many objects the condition of OOP gone mad:
For example, I had a discussion with a colleague once on how to represent depth in an oil well for software we were writing. I said “Let’s just use a number.”
double depth;My suggestion was laughed off as hopelessly crude. We need to create depth objects! And not just C++ objects, COM objects! We couldn’t send a
doubleout into the world without first wrapping it in the overhead of an object.
Wednesday, July 17, 2013
Martin Thompson on GC
Another great post from Martin Thompson, Java Garbage Collection Distilled. In spite of the unassuming title, this is a must-read for advanced Java developers. Introduction:
Serial, Parallel, Concurrent, CMS, G1, Young Gen, New Gen, Old Gen, Perm Gen, Eden, Tenured, Survivor Spaces, Safepoints, and the hundreds of JVM startup flags. Does this all baffle you when trying to tune the garbage collector while trying to get the required throughput and latency from your Java application? If it does then do not worry, you are not alone. Documentation describing garbage collection feels like man pages for an aircraft. Every knob and dial is detailed and explained but nowhere can you find a guide on how to fly. This article will attempt to explain the tradeoffs when choosing and tuning garbage collection algorithms for a particular workload.
The focus will be on Oracle Hotspot JVM and OpenJDK collectors as those are the ones in most common usage. Towards the end other commercial JVMs will be discussed to illustrate alternatives.
I especially like his diagram for G1:
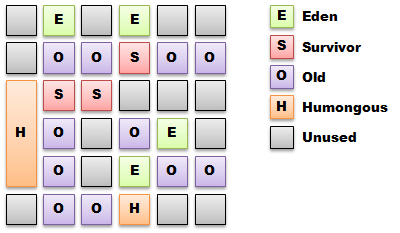
Enjoy!
Tuesday, July 09, 2013
Example RMI code
Syed Muhammad Humayun posts Java Remote Method Invocation (RMI) with Secure Socket Layer (SSL), a succinct, clear example of using SSL with vanilla RMI in Java. RMI never had good examples that I saw, Sayed's contribution goes into toolbox of tricks.
Monday, June 24, 2013
G1GC Overview
Richard Warburton posts on the G1 GC algorithm in Java 6+, part of a series on JVM collectors.
Key takeaway:

Sunday, June 23, 2013
Thursday, May 30, 2013
Bloaty XMLBeans
Nikita Salnikov-Tarnovski writes Reducing memory consumption by 20x. One change, dropping XML beans, reduced footprint from 1.5G to 214M. It's not quite that simple, and there's more tuning for the headline 20x improvement, but this is the gist of it. Amazing.

Tuesday, May 28, 2013
For old time's sake, Uncle Bob
I forgot how good Uncle Bob can be. Thank you, The Old Reader: Transformation Priority and Sorting. Quoting:
In this post we explore the Transformation Priority Premise in the context of building a sort algorithm.
We also explore comic books as a pedagogical tool.

Want to read the rest? (In the interest of fair use you should follow the link.)
Sunday, May 26, 2013
Is it live, or is it structured deferral?
A delightful ACM paper by Paul E. McKenney, Structured Deferral: Synchronization via Procrastination. The "motivating example":
In this example, Schrödinger would like to construct an in-memory database to keep track of the animals in his zoo. Births would of course result in insertions into this database, while deaths would result in deletions. The database is also queried by those interested in the health and welfare of Schrödinger's animals.
Schrödinger has numerous short-lived animals such as mice, resulting in high update rates. In addition, there is a surprising level of interest in the health of Schrödinger's cat,19 so much so that Schrödinger sometimes wonders whether his mice are responsible for most of these queries. Regardless of their source, the database must handle the large volume of cat-related queries without suffering from excessive levels of contention. Both accesses and updates are typically quite short, involving accessing or mutating an in-memory data structure, and therefore synchronization overhead cannot be ignored.
Schrödinger also understands, however, that it is impossible to determine exactly when a given animal is born or dies. For example, suppose that his cat's passing is to be detected by heartbeat. Seconds or even minutes will be required to determine that the poor cat's heart has in fact stopped. The shorter the measurement interval, the less certain the measurement, so that a pair of veterinarians examining the cat might disagree on exactly when death occurred. For example, one might declare death 30 seconds after the last heartbeat, while another might insist on waiting a full minute, in which case the veterinarians disagree on the state of the cat during the second half of the minute after the last heartbeat.
Fortunately, Heisenberg8 has taught Schrödinger how to cope with such uncertainty. Furthermore, the delay in detecting the cat's passing permits use of synchronization via procrastination. After all, given that the two veterinarians' pronouncements of death were separated by a full 30 seconds, a few additional milliseconds of software procrastination is perfectly acceptable.
Among the pleasures in this paper: Linux's RCU, hazard pointers, and "read-only cat-heavy performance of Schrödinger's hash table".
Enjoy!
Friday, May 24, 2013
If it's broke, don't fix it
Saul Caganoff writes Netflix: Dystopia as a Service on Adrian Cockroft keynote describing Netflix's seemingly impossible infrastructure. The opening:
"As engineers we strive for perfection; to obtain perfect code running on perfect hardware, all perfectly operated." This is the opening from Adrian Cockroft, Cloud Architect at Netflix in his recent Keynote Address at Collaboration Summit 2013. Cockroft continues that the Utopia of perfection takes too long, that time to market trumps quality and so we compromise. But rather than lamenting the loss of "static, better, cheaper" perfection, Cockroft describes how the Netflix "Cloud Native" architecture embraces the Dystopia of "broken and inefficient" to deliver "sooner" and "dynamic". Cockroft says that "the new engineering challenge is not to construct perfection but to construct highly agile and highly available services from ephemeral and often broken components."
Were I looking for a new challenge, as interesting as Google is, I'd go to Netflix—unless I got to work on asteroid mining!
Do you read the Netflix Tech Blog — why not?
Thursday, May 23, 2013
Census data with Bash
For fun I played with the 2012 US census data on metropolitan areas. I wanted to answer a simple questions, which "big" cities are growing the fastest?
First a note on file format. If you are splitting this line on comma, you want 3 fields:
apple,"banana,split",coconut
But it is easy to get 4 fields instead. My quick fix was to change comma to colon for field separators with this bit of python in a file named "csv-comma-to-colon.py":
import csv
import fileinput
for row in csv.reader(fileinput.input()):
print(':'.join(row)) Simple, effective. An alternative I did not explore enough was csvprintf.
Once I have colon field separators, the rest writes itself. Seeing the CSV file from the census has non-data header and footer lines, I filter and sort:
sed '/^[^1-9]/d' CBSA-EST2012-05.csv \
| python ./csv-comma-to-colon.py \
| sort -t: -k4 -nr \
| head -50 \
| sort -t: -k6 -nr \
| head -10 \
| cut -d: -f2,4,6 Breaking it down:
- Skip non-data lines from the CSV file.
- Convert comma field separators to colon.
- Reorder the data by city size, descending.
- Keep only the top 50 biggest cities.
- Reorder the remaining data by growth rate.
- Keep only the 10 fastest growing cities.
- Display only these columns: city name, current population, growth rate.
There may be better ways, this was enough for some quick fun. I would be remiss not to show the results nicely formatted for the web:
| Metropolitan Area | Population | Growth |
|---|---|---|
| Austin-Round Rock, TX | 1,834,303 | 3.0 |
| Raleigh, NC | 1,188,564 | 2.2 |
| Orlando-Kissimmee-Sanford, FL | 2,223,674 | 2.2 |
| Houston-The Woodlands-Sugar Land, TX | 6,177,035 | 2.1 |
| Dallas-Fort Worth-Arlington, TX | 6,700,991 | 2.0 |
| San Antonio-New Braunfels, TX | 2,234,003 | 1.9 |
| Phoenix-Mesa-Scottsdale, AZ | 4,329,534 | 1.8 |
| Denver-Aurora-Lakewood, CO | 2,645,209 | 1.8 |
| Nashville-Davidson--Murfreesboro--Franklin, TN | 1,726,693 | 1.7 |
| Las Vegas-Henderson-Paradise, NV | 2,000,759 | 1.7 |
Wednesday, May 22, 2013
Netflix delivers Java tools
Netflix continues as a Java technology powerhouse, delivering one open source tool or framework after another. The latest posting from their excellent blog is Brian Moore on Garbage Collection Visualization, a tool for turning gc.log into usable graphs.
The JVM heap teaser shot:

Sunday, May 19, 2013
Java for Fun - Shazam with Roy van Rijn
Roy van Rijn writes Creating Shazam in Java. This is way more fun than most Java posts:
If I record a song and look at it visually it looks like this:
(all the red dots are ‘important points’)

(I would hang that on my wall, wouldn't you?)
He has more fun code on GitHub.
Thursday, May 16, 2013
Escaping TFS
From 2011 Derek Hammer writes TFS is destroying your development capacity with advice on escaping TFS. How little has changed.
UPDATED: A delightful take from Prasanna Pendse, Top 10 Version Control Features of TFS.
Wednesday, May 15, 2013
Code imitates math
Jeff Preshing posted in 2010 High-Resolution Mandelbrot in Obfuscated Python, Python code to draw the Mandelbrot set (h/t Marcus Holtermann). Can you spot the relationship?
_ = (
255,
lambda
V ,B,c
:c and Y(V*V+B,B, c
-1)if(abs(V)<6)else
( 2+c-4*abs(V)**-0.4)/i
) ;v, x=1500,1000;C=range(v*x
);import struct;P=struct.pack;M,\
j ='<QIIHHHH',open('M.bmp','wb').write
for X in j('BM'+P(M,v*x*3+26,26,12,v,x,1,24))or C:
i ,Y=_;j(P('BBB',*(lambda T:(T*80+T**9
*i-950*T **99,T*70-880*T**18+701*
T **9 ,T*i**(1-T**45*2)))(sum(
[ Y(0,(A%3/3.+X%v+(X/v+
A/3/3.-x/2)/1j)*2.5
/x -2.7,i)**2 for \
A in C
[:9]])
/9)
) )
Tuesday, May 14, 2013
Praising the opponents with PostgreSQL
I just read an unusual article, PostgreSQL at a glance, a lengthy, favorable review of a competing product by Kim Sung Kyu, Senior Software Engineer at CUBRID. The opening:
PostgreSQL shows excellent functionalities and performance. Considering its high quality, it may seem strange that PostgreSQL is not more popular. However, PostgreSQL continues to make progress. This article will discuss this database.
This is a good review of PostgreSQL, on CUBRID's blog no less. To openly write about alternative products speaks well of your own.
Linux C10M
Great list, the key is separation of concerns: The Secret To 10 Million Concurrent Connections -The Kernel Is The Problem, Not The Solution.
Wednesday, May 08, 2013
More Zing for Java
From LMAX Exchange Getting Up To 50% Improvement in Latency From Azul's Zing JVM:
The results LMAX Exchange are seeing are remarkable: a 10-20% improvement in the mean latency, increasing to around a 50% improvement at the 99th percentile. Moreover
At the max/99.99th percentile with HotSpot the number would jump all over the place so it is hard to produce a relative comparison, except to say that the Zing values are much more stable. A bad run with HotSpot could easily be an order of magnitude worse.
In terms of throughput
Zing gives us the ability to lift what we call our "red-line" - the throughput value at which the latency starts to drop off a cliff. This effect often manifests as a second order effect of GC pauses. If we get a stall that is sufficiently long, we will start to drop packets. The process of packet redelivery can create back-pressure throughout the rest of the system sending client latencies through the roof. Having a more efficient collector with very short predictable pauses should allow us to increase our "red-line".
Most eye popping for me:
Whilst these figures are impressive, the variations, caused primarily by stop-the-world pauses in the CMS collector that is part of HotSpot, are becoming a significant problem. LMAX Exchange tried upgrading to the CMS version in JDK 7, but encountered around a 20% increase in the length of GC pauses for the same work load. The reasons for this weren't entirely clear, but Barker suggested it was probably down to a need to re-tune the collector. That Zing's collector (C4) typically requires little or no tuning was a major selling point for LMAX Exchange.
I think that we really needed to do retuning of our GC setting and investigating whether JDK 7 specific options like -XX:+UseCondCardMark and -XX:+UseNUMA should be applied. One of the other big reasons to go with Azul is the reduced need to tune the collector. The general recommendation is that you should re-tune from scratch on each new version of the JDK, which sounds fine in theory, but can be impractical. Collector tuning in Oracle JDK is essentially walking through a large search space for a result that meets your needs. Experience, knowledge and guess-work can crop significant chunks off that search space, but even then an extensive tuning exercise can take weeks. For example, our full end-to-end performance test takes 1 hour (10 minutes build & deploy, 10 minutes warm-up, 40 minutes testing), so I could reasonably run 8 runs a day. If you consider the number of different collectors (CMS, Parallel, Serial,...) and all of their associated options (new and old sizes, survivor spaces, survivor ratios,...) how many runs do I need to do to get effective coverage of that search space: 20, 30, more? With Zing the defaults work significantly better than a finely tuned Oracle JDK. We still have some investigation over whether we can get a bit more out of the Zing VM through tuning (e.g. fewer collector threads as our allocation rate is relatively low). However, tuning Zing is just that, i.e. looking to eke out the very best from the system; compared to the Oracle JDK where tuning from the defaults can be the difference between usable and unusable. The effort involving in tuning does come with an opportunity cost. I would much rather have the developers that would typically be involved with GC tuning (they are probably the ones that have the best working knowledge of software performance) be focusing on improving the performance of other areas of the system.
Concluding:
Part of the reason Zing is so attractive to these companies is that it remains the only collector that eliminates stop-the-world pauses from the young generation as well as the old generation. Whilst young generation pauses are shorter, where an application is particularly performance sensitive they still matter. As a result, Tene told us, "All we have to do is point to newgen pauses in other JVMs and say: 'those too will be gone'."
...Furthermore, the fact that it can handle multi-GB-per-sec allocations without worsening latencies or pauses, makes it very appealing for developers who have been trying hard not to allocate things because "it hurts". With Zing, you can use plenty of memory to go fast, instead of trying to avoid using it so that things won't hurt and jitter.
For production use Zing is priced on an annual subscription/server. Unsurprisingly the vendor is reluctant to reveal pricing information, though it is in line with a supported Oracle or IBM JVM.
The Future of Java
Kindly transcribed in Cliff Click, Charlie Hunt and Doug Lea on 'The Future of the JVM'. Juicy bit:
My View: worst feature was a synchronized StringBuffer. I have blogged about this a couple of times. I would add mutable Date objects.
Preaching to the choir, brother.
Thursday, May 02, 2013
Agile is Money
Fascinating read by Daniel Greening: Agile Capitalization, found thanks to Jeff Sutherland. As Jeff describes:
In many companies, agile software development is misunderstood and misreported, causing taxation increases, higher volatility in Profit and Loss (P&L) statements and manual tracking of programmer hours. One large company’s confused finance department expenses all agile software development and capitalizes waterfall development; projects in this company that go agile see their headcounts cut by 50%. This discourages projects from going agile.
Scrum’s production experiment framework can align well with the principles of financial reporting. In this article, the author explains the basics of capitalization and expensing, and offers a financial framework for capitalizing agile projects that can be understood by both accountants and agile teams.
I'll take double headcount, please. Daniel's introduction:
In many companies, agile software development is misunderstood and misreported, causing taxation increases, higher volatility in Profit and Loss (P&L) statements and manual tracking of programmer hours. I claim Scrum teams create production cost data that are more verifiable, better documented, and more closely aligned with known customer value than most waterfall implementations. Better reporting can mean significant tax savings and greater investor interest. Agile companies should change their financial reporting practices to exploit Scrum’s advantages. It might not be easy, but I did it.
Scrum’s production experiment framework aligns perfectly with the principles of financial reporting.
When I restructured software capitalization according to the principles here during an all-company Scrum transition at a 900-person software company, we delighted auditors, gave more insight to upper management and raised more internal money to hire developers. We gained millions in tax savings, by using Scrum Product Backlog Items to more accurately document and capitalize our software work.
I hope to arm you with perspectives and resources to make the accounting argument for agile capitalization, potentially reducing your company’s tax burden, increasing available funds for engineers, and making your auditors happy
Agile is real money.
Monday, April 29, 2013
Moving a git repository to the subdirectory of another repository
How do I move a git repository to be the subdirectory of another repository? is a question answered umpteen times, and all answers vary somewhat. For my needs, this suffices:
#!/bin/bash case $# in 3 ) old_repo=$1 new_repo=$2 new_name=$3 ;; * ) echo "$0: old_repo new_repo new_name" ; exit 2 ;; esac set -e trap 'rm -rf $old_work $new_work' EXIT old_work=$(mktemp -d) new_work=$(mktemp -d) git clone $old_repo $old_work git clone $new_repo $new_work cd $old_work # If new_name contains commas, edit the sed command accordingly git filter-branch --index-filter 'git ls-files -s | sed "s,\t\"*,&'$new_name'/," | GIT_INDEX_FILE=$GIT_INDEX_FILE.new git update-index --index-info && mv $GIT_INDEX_FILE.new $GIT_INDEX_FILE' HEAD cd $new_work git remote add $new_name $old_work git pull $new_name master git push
-XshowSettings
A java flag I hadn't noticed before but wish I had: -XshowSettings. It dumps out the system properties and a guess at which VM to use (server v. client), among other things. Look here for more magic -X flags.
Monday, April 15, 2013
More good Java 8, living with null
Edwin Dalorzo posts wonderfully on Java 8 Optional Objects: what is the problem, how it is handled in other languages, what Java 8 does about it. It all boils down to the "billion dollar mistake": null.
Thursday, April 11, 2013
Moving, but not the blog

Monday morning, April 1st, my family and I relocate for work to Manila from Houston. My employer, Macquarie Bank, is a conservative, successful investment bank from Australia. 2008 brought difficulties for many firms in the banking industry; for Macquarie it brought opportunity.
I encourage anyone looking for the right work environment to consider Macquarie. For many of my mates this is their first and only job out of college, writing building impressive systems from solid code. It is my only job as satisfying as ThoughtWorks.
Only my family and me are moving. binkley's BLOG remains where it is.
Map view of list key-value pairs in Java
Long time no code.
Example use
import ListMap;
import javax.annotation.Nonnull;
import java.util.ArrayList;
import static java.util.Arrays.asList;
public class AttributesMap
extends ListMap<FooItem, String, String> {
public AttributesMap(final FooOperations foos, final String cookie) {
super(new FooItems(foos, cookie), new FooItemConverter());
}
private static class FooItems
extends ArrayList<FooItem> {
private final FooOperations foos;
private final String cookie;
private FooItems(final FooOperations foos, final String cookie) {
super(asList(foos.getAttributes(cookie)));
this.foos = foos;
this.cookie = cookie;
}
@Override
public FooItem set(final int index, final FooItem element) {
final FooItem oldElement = super.set(index, element);
save();
return oldElement;
}
@Override
public void add(final int index, final FooItem element) {
super.add(index, element);
save();
}
@Override
public FooItem remove(final int index) {
final FooItem oldElement = super.remove(index);
save();
return oldElement;
}
private void save() {
try {
foos.setAttributes(cookie, toArray(new FooItem[size()]));
} catch (final BadDataRef e) {
throw new UserRuntimeException(e);
}
}
}
private static final class FooItemConverter
implements Converter<FooItem, String, String> {
@Nonnull
@Override
public FooItem toElement(@Nonnull final String key, final String value) {
return new FooItem(key, value);
}
@Nonnull
@Override
public Entry<String, String> toEntry(@Nonnull final FooItem element) {
return new SimpleEntry<>(element.tag, element.value);
}
}
} ListMap utility class
import javax.annotation.Nonnull;
import javax.annotation.concurrent.NotThreadSafe;
import java.util.AbstractMap;
import java.util.AbstractSet;
import java.util.List;
import java.util.ListIterator;
/**
* {@code ListMap} provides a read-write map view over a list of elements. The elements must
* provide a key-value pair structure; keys must {@link #equals(Object)} and {@link #hashCode()}.
* <p/>
* All map mutating methods also mutate the underlying list. Mutating the underlying list also
* mutates the map view.
* <p/>
* There is no synchronization; instances are not thread safe.
*
* @param <T> the type of list elements
* @param <K> the type of map keys
* @param <V> the type of map values
*
* @author <a href="mailto:binkley@alumni.rice.edu">B. K. Oxley (binkley)</a>
*/
@NotThreadSafe
public class ListMap<T, K, V>
extends AbstractMap<K, V> {
private final List<T> elements;
private final Converter<T, K, V> converter;
/**
* Creates a new {@code ListMap} for the given <var>elements</var> and <var>converter</var>.
*
* @param elements the list of elements underlying the map, never missing
* @param converter the converter between elements and entry objects, never missing
*/
public ListMap(@Nonnull final List<T> elements, @Nonnull final Converter<T, K, V> converter) {
this.elements = elements;
this.converter = converter;
}
/**
* {@inheritDoc}
* <p/>
* Updates the underlying list of elements.
*/
@Override
public V put(final K key, final V value) {
final ListIterator<T> lit = elements.listIterator();
while (lit.hasNext()) {
final T element = lit.next();
final Entry<K, V> entry = converter.toEntry(element);
if (entry.getKey().equals(key)) {
elements.set(lit.nextIndex() - 1, converter.toElement(key, value));
return entry.getValue();
}
}
lit.add(converter.toElement(key, value));
return null;
}
/**
* {@inheritDoc}
*
* @return a specialized set view of the entries over the element list
*/
@Override
@Nonnull
public ListMapSet entrySet() {
return new ListMapSet();
}
/**
* Exposes the underlying list of elements backing the map view.
*
* @return the element list, never missing
*/
@Nonnull
public List<T> elements() {
return elements;
}
/**
* Converts between elements and entry objects.
*
* @param <T> the type of list elements
* @param <K> the type of map keys
* @param <V> the type of map values
*/
public static interface Converter<T, K, V> {
/**
* Converts to an element instance from a map <var>key</var>-<var>value</var> pair.
*
* @param key the map key, never missing
* @param value the map value, optional
*
* @return the corresponding list element, never missing
*/
@Nonnull
T toElement(@Nonnull final K key, final V value);
/**
* Converts to a map entry instance from a list <var>element</var>.
*
* @param element the list element, never missing
*
* @return the corresponding map entry, never missing
*/
@Nonnull
Entry<K, V> toEntry(@Nonnull final T element);
}
/**
* Backing set for {@link ListMap} exposed as a separate type so callers may access a {@link
* #iterator() list iterator} and a list iterator {@link #iterator(int) offset by an index}.
*/
public final class ListMapSet
extends AbstractSet<Entry<K, V>> {
/**
* {@inheritDoc}
*
* @see java.util.List#listIterator()
*/
@Override
@Nonnull
public ListMapIterator iterator() {
return new ListMapIterator();
}
@Override
public int size() {
return elements.size();
}
@Override
public boolean add(final Entry<K, V> entry) {
return elements.add(converter.toElement(entry.getKey(), entry.getValue()));
}
/** @see List#listIterator(int) */
@Nonnull
public ListMapIterator iterator(final int index) {
return new ListMapIterator(index);
}
}
/**
* Entry set iterator for {@link ListMapSet} exposed as a separate type.
*
* @see ListMapSet#iterator() list iterator
* @see ListMapSet#iterator(int) offset by an index
*/
public final class ListMapIterator
implements ListIterator<Entry<K, V>> {
private final ListIterator<T> it;
public ListMapIterator() {
it = elements.listIterator();
}
public ListMapIterator(final int index) {
it = elements.listIterator(index);
}
@Override
public boolean hasNext() {
return it.hasNext();
}
@Override
public Entry<K, V> next() {
return new ListMapEntry(it.next());
}
@Override
public boolean hasPrevious() {
return it.hasPrevious();
}
@Override
public Entry<K, V> previous() {
return new ListMapEntry(it.previous());
}
@Override
public int nextIndex() {
return it.nextIndex();
}
@Override
public int previousIndex() {
return it.previousIndex();
}
@Override
public void remove() {
it.remove();
}
@Override
public void set(final Entry<K, V> entry) {
it.set(converter.toElement(entry.getKey(), entry.getValue()));
}
@Override
public void add(final Entry<K, V> entry) {
it.add(converter.toElement(entry.getKey(), entry.getValue()));
}
private class ListMapEntry
implements Entry<K, V> {
private final T element;
ListMapEntry(final T element) {
this.element = element;
}
@Override
public K getKey() {
return converter.toEntry(element).getKey();
}
@Override
public V getValue() {
return converter.toEntry(element).getValue();
}
@Override
public V setValue(final V value) {
final Entry<K, V> oldEntry = converter.toEntry(element);
elements.set(nextIndex() - 1, converter.toElement(oldEntry.getKey(), value));
return oldEntry.getValue();
}
}
}
}
Monday, March 25, 2013
EJBs considered harmful, once more with feeling
Though not his point Piotr Nowicki in his post, EJB Inheritance is Different From Java Inheritance, reminds me why EJBs should be considered harmful.
Monday, March 11, 2013
More Bob: Sat ci sat bene
More of the indisputable Uncle Bob, The Frenzied Panic of Rushing:
James and I had just ordered Gin and Tonics from the airport bar and returned to the waiting area, when we saw a group of the TWers frantically working on their laptops. We asked someone what was going on, and were told that they were racing to see who could implement Langton's Ant quickest.
James and I looked at each other, nodded, opened a laptop, and quietly began to pair-program. We followed our disciplines, wrote test-first, kept the code clean, got it working after a few minutes, and then closed the laptop. We looked up, and the young twenty-thirty-something TWers were still expending copious energies in a fit of frantic coding. The frenzied intensity of their effort, driven by the panic of potential loss, was evident in their gestures and expressions. We, the two fifty-something programmers, smiled, clinked our Gin and Tonics, and sat back to enjoy the show being put on by all those young turks who never even guessed that they had been calmly bested by two of their seniors who had the experience and wisdom to know that the only way to go fast is to go well.
I am happy I joined ThoughtWorks after the story took place lest I have been one of the frantic foragers.
Thursday, March 07, 2013
The JUnit forest
Edmund Kirwan damns the ubiquitous JUnit in JUnit's evolving structure. What's the problem? — galloping interdependencies. As a bonus, a spiffy graphical timeline of JUnit's structure.
Wednesday, March 06, 2013
Skipping TDD
Uncle Bob, as usual, is a pleasure to read, to wit, The Pragmatics of TDD. Highlights:
- I don't write tests for getters and setters. Doing so is usually foolish. Those getters and setters will be indirectly tested by the tests of the other methods; so there's no point in testing them directly.
- I don't write tests for member variables. They too will be tested indirectly.
- I don't write tests for one line functions or functions that are obviously trivial. Again, they'll be tested indirectly.
- I don't write tests for GUIs. GUIs require fiddling. You have to nudge them into place by changing a font size here, an RGB value there, an XY position here, a field width there. Doing that test-first is silly and wasteful.
- In general I don't write tests for any code that I have to "fiddle" into place by trial and error. But I separate that "fiddling" code from code that I am surer of and can write tests for.
- A few months ago I wrote an entire 100 line program without any tests. (GASP!)
- I usually don't write tests for frameworks, databases, web-servers, or other third-party software that is supposed to work. I mock these things out, and test my code, not theirs.
Tuesday, March 05, 2013
Plugging a leaky ship
Plumbr's Nikita Salnikov-Tarnovski writes Hunting down memory leaks: a case study. Quoting:
A week ago I was asked to fix a problematic webapp suffering from memory leaks. How hard can it be, I thought – considering that I have both seen and fixed hundreds of leaks over the past two years or so.
But this one proved to be a challenge. 12 hours later I had discovered no less than five leaks in the application and had managed to fix four of them. I figured it would be an experience worth sharing. For the impatient ones – all in all I found leaks from
- MySQL drivers launching background threads
- java.sql.DriverManager not unloaded on redeploys
- BoneCP loading resources from the wrong classloaders
- Datasource registered into a JNDI tree blocking unloading
- Connection pool using finalizers tied to Google’s implementation of reference queue running in a separate thread
Of course, there's more.
Monday, February 25, 2013
TCP traceroute
Peteris Krumins posts on TCP Traceroute, a nifty trick to "see" through firewalls. His pudding:
# traceroute -T -p 80 www.microsoft.com traceroute to www.microsoft.com (65.55.57.27), 30 hops max, 60 byte packets 1 50.57.125.2 (50.57.125.2) 0.540 ms 0.629 ms 0.709 ms 2 core1-aggr701a-3.ord1.rackspace.net (184.106.126.50) 0.486 ms 0.604 ms 0.691 ms 3 corea.ord1.rackspace.net (184.106.126.128) 0.511 ms corea.ord1.rackspace.net (184.106.126.124) 0.564 ms 0.810 ms 4 bbr1.ord1.rackspace.net (184.106.126.147) 1.339 ms 1.310 ms bbr1.ord1.rackspace.net (184.106.126.145) 1.307 ms 5 chi-8075.msn.net (206.223.119.27) 3.619 ms 2.560 ms 2.528 ms 6 * 204.152.140.35 (204.152.140.35) 3.640 ms * 7 ge-7-0-0-0.co1-64c-1a.ntwk.msn.net (207.46.40.94) 52.523 ms xe-0-2-0-0.ch1-96c-2b.ntwk.msn.net (207.46.46.49) 3.825 ms xe-1-2-0-0.ch1-96c-2b.ntwk.msn.net (207.46.46.53) 3.355 ms 8 xe-0-1-0-0.co1-96c-1a.ntwk.msn.net (207.46.33.177) 61.042 ms 61.032 ms 60.457 ms 9 * * xe-5-2-0-0.co1-96c-1b.ntwk.msn.net (207.46.40.165) 100.069 ms 10 65.55.57.27 (65.55.57.27) 53.868 ms 53.038 ms 52.097 ms
Monday, February 18, 2013
Friday, February 15, 2013
On being the bearer of bad news
Elena Yatzeck writes 6 Steps To Success With Your Executive Boss, or "On being the bearer of bad news" (my title), another good post on the timeless theme, Do The Right Thing.
Thursday, February 07, 2013
The Java enum factory
This comes up in interviews with intermediate programmers (and some seniors), the "enum factory" in Java:
public final class Money {
// Infrequent that new currencies created,
// old currencies never vanish, just fade away
public enum Currency {
USD, PHP; // And many more
// Additional fields as needed, e.g., locale
public Money print(final BigDecimal amount) {
return new Money(this, amount);
}
}
private final Currency currency;
private final BigDecimal amount;
private Money(final Currency currency, final BigDecimal amount) {
this.currency = currency;
this.amount = amount;
}
// Appropriate methods
} And elsewhere with static imports:
Money pocket = asList(USD.print(ONE), PHP.print(TEN));
The key observations:
- Amounts of money are intimately attached to a particular currency
- Currency has few qualities not attached to money
- Ok to add more currencies through code
- Code reads better with factory than without
Tuesday, February 05, 2013
Mana on leadership
Mana of Geek Diva posts on leadership. Key point (emphasis mine):
When I see people who I consider good leaders, be they of any age, gender, height or ethnicity, I see one thing that they do very well. They make decisions quickly. Quickly does not mean recklessly. It just means that they make a decision knowing that if it isn't right then they can correct at a later time.
Java 8 lambdas and all that
Lovely post from Anton Arhipov at JRebel, Java 8: The First Taste of Lambdas. Kudos for javap decompilation for an "under the hood" explanation. His conclusion:
We can definitely say that lambdas and the accompanied features (defender methods, collections library improvements) will have a great impact on Java very soon. The syntax is quite nice and once developers realize that these features provide value to their productivity, we will see a lot of code that leverages these features.
It was quite interesting for me to see what lambdas are compiled to and I was very happy when I saw the total utilization of the invokedynamic instruction in action without any anonymous inner classes involved at all.
Friday, February 01, 2013
Wednesday, January 16, 2013
Superior teams
Venkatesh Krishnamurthy writes The 4 Ingredients of Building Hyper-Productive Teams. What he means are agile teams, quoting Jeff Sutherland:
We define Hyper-Productivity here at 400% higher velocity than average waterfall team velocity with correspondingly higher quality. The best Scrum teams in the world average 75% gains over the velocity of waterfall teams with much higher quality, customer satisfaction, and developer experience.
Agile for me, though worded awkwardly: how do the best scrum teams compare to the best waterfall teams?
Friday, January 11, 2013
GapList, an alternative to ArrayList and LinkedList
Thomas Mauch presents GapList, an alternative to ArrayList and LinkedList in Java, with the best performance behaviors of both: fast random reads and compact, cache-friendly storage like ArrayList, fast random updates like LinkedList.
Monday, January 07, 2013
Marz on Lambda Architecture
Nathan Marz writes on Big Data Lambda Architecture, promoting his upcoming book from Manning, Big Data. It's a comprehensible take on big data architectures. (See Chapter 1 [pdf].)
In a nutshell:
Computing arbitrary functions on an arbitrary dataset in real time is a daunting problem. There is no single tool that provides a complete solution. Instead, you have to use a variety of tools and techniques to build a complete Big Data system.
The lambda architecture solves the problem of computing arbitrary functions on arbitrary data in real time by decomposing the problem into three layers: the batch layer, the serving layer, and the speed layer.
Subscribe to:
Posts (Atom)